Improving a content filtering algorithm by using an indexing mechanism
Introduction
The landscape of online sports betting in the United States has undergone a major shift in recent years, transitioning from a prohibited activity to a booming industry. For decades, strict regulations and federal laws barred the majority of Americans from enjoying the thrills of legal online wagering. This paradigm has recently changed and now instead of federal oversight, we have individual states crafting their own rules of what can and cannot be done in terms of online sports betting. In response to this significant shift in the landscape of online sports betting in the United States, the company I am currently working on created a content filtering system to ensure strict compliance with the laws and regulations at the state level. This content filtering system is designed to meticulously examine and manage the content accessible through our platform, ensuring that it aligns with the unique requirements and restrictions set forth by each individual state by identifying and blocking bets on prohibited sports events. In this article we will talk about the high level design approach used to appropriately filter the sports betting catalogue in each state and how we used indexing to be able to properly scale the system.
Hierarchies and Filtering Rules
The major concepts used in this content filtering system are hierarchies and filtering rules. We’ll start by defining these concepts
Hierarchies
A hierarchy is the concept used to represent the sport betting catalogue. A hierarchy is composed by a sport, a competition, an event and a market (in reality it is a bit more complex than this but this should be enough to describe the problem at hands). An example of a possible hierarchy would be something like:
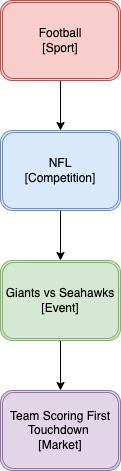
The sport, competition and event attributes describe the sport event to which the bet refers to and the market attribute describes the type of bet. In the example showed above we have a hierarchy that allow us to bet on the team which will score the first touchdown on the Giants vs Seahawks NFL game.
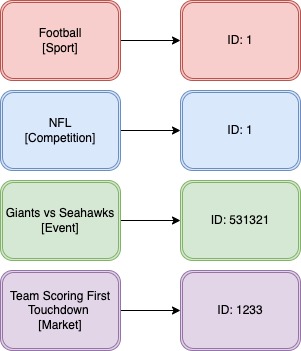
It is also important to note that each level of the hierarchy is identified by an ID. So using the example above we could have something like:
Filtering Rules
The filtering rules are the concept that allow us to specify whether a given hierarchy should be blocked or unblocked. Each state has its own set of rules to allow us to be aligned with each specific state legislation. These rules are created using a custom DSL and allow to block or unblock sports betting catalogue based on IDs and can target any level of a given hierarchy. The specific format of the rules is proprietary so I cannot reveal it but we can create rules that can do the following actions:
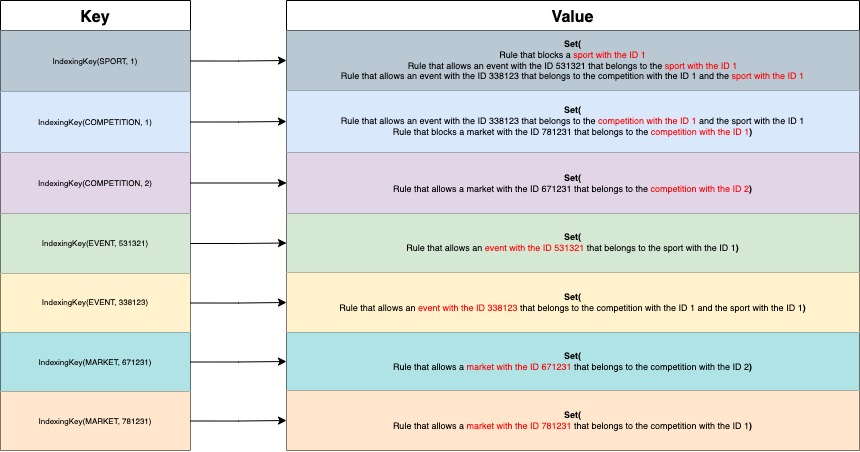
- Block a sport with the ID 1
- Allow an event with the ID 531321 that belongs to the sport with the ID 1
- Allow an event with the ID 338123 that belongs to the competition with the ID 1 and the sport with the ID 1
- Allow a market with the ID 671231 that belongs to the competition with the ID 2
- Block a market with the ID 781231 that belongs to the competition with the ID 1
Each hierarchy can have multiple rules affecting it and we have a custom algorithm to decide which rule prevails.
Crossing the hierarchies with the filtering rules
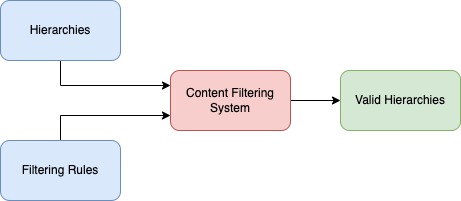
What our content filtering system does is to cross the ruleset of each state with the available hierarchies and output the list of valid hierarchies per state. The following diagram represents the high level architecture of the system:
Problem
At first what our content filtering system did was to confront the whole ruleset against each existent hierarchy. This worked well for quite a while but eventually we started hitting in performance problems when the size of the ruleset and the catalogue started to grow a lot. Initially we implemented a distributed algorithm to solve the performance problems by leveraging Akka to achieve horizontal scaling (maybe I’ll write an article about that in the future! :D). That solved our performance problems at the time but after a while it started to fall short again once the ruleset and the catalogue grew even further. At a given point we had states with more than 100.000 hierarchies and 40.000 rules. This resulted in each hierarchy being confronted against each one of the 40.000 rules. This obviously didn’t scale. At this point we came to the conclusion that throwing more computer power to the problem at hands would not be enough so we started to think about a new solution to address it at its core.
Solution
The Eureka moment
A common meme used to depict software engineer job interviews is: If you don't know the answer to the problem just throw a hashmap at it!. While this meme is humorous and somewhat exaggerated, there’s some truth to it in the sense that data structures like hashmaps are often fundamental tools used in solving various programming problems. Hashmaps are key-value data stores that allow for O(1) data retrieval, meaning that regardless of the size of the dataset, you can access the desired information in constant time (assuming no hash collisions of course!). This characteristic significantly affects performance, especially when dealing with large-scale applications and complex algorithms, as it ensures efficient data access and manipulation, making hashmaps a go-to choice for many software engineering problems.
After thinking a bit about the system we came to the realization that most of the hierarchies would only have a few rules affecting them while all the other rules were completely irrelevant. For example a rule that blocks hierarchies associated with the sport ID 2 is completely irrelevant to the hierarchy showed in the image above since that hierarchy is associated to the sport with the ID 1. After we noticed that we figured it out that we were wasting a lot of computational power in processing hierarchies against rules that were irrelevant. Then in order to address this problem we came up with an idea of indexing the ruleset using an hashmap to guarantee that for each hierarchy we would only process the rules that were strictly associated with it. With this small tweak we were able to dramatically reduce the required processing power to execute the filtering algorithm.
The implementation details
The first step was to index the rules by placing them on an hashmap that would allow us to fetch only the relevant rules for each specific hierarchy. For this we created a IndexingKey class to be used as key on the hashmap of indexed rules and we’ve created an hashmap - indexedRules - to associate each indexing key with the correspondent set of rules.
enum HierarchyType {
SPORT,
COMPETITION,
EVENT,
MARKET
}
record IndexingKey(HierarchyType hierarchyType, String indexingValue) {}
private Map<IndexingKey, Set<String>> indexedRules;
If we were indexing the rules presented in the filtering rules section above we would have something like this:
After having the rules indexed we just needed to retrieve the rules that are strictly related to the hierarchy we’re analyzing. We did that by building a list of all the possible indexing keys for that hierarchy which we can then use to fetch the relevant rules from the indexed hashmap. We then collect those rules to a Set to avoid processing repeated rules.
record HierarchyData(String id) {}
record Sport(HierarchyData hierarchyData) {}
record Competition(Sport sport, HierarchyData hierarchyData) {}
record Event(Competition competition, HierarchyData hierarchyData) {}
record Market(Event event, HierarchyData hierarchyData) {}
public Set<String> getRulesetForMarket(Market market) {
Set<IndexingKey> relevantKeys = Set.of(
new IndexingKey(HierarchyType.MARKET, market.hierarchyData.id),
new IndexingKey(HierarchyType.EVENT, market.event.hierarchyData.id),
new IndexingKey(HierarchyType.COMPETITION, market.event.competition.hierarchyData.id),
new IndexingKey(HierarchyType.SPORT, market.event.competition.sport.hierarchyData.id)
);
return relevantKeys.stream()
.map(indexingKey -> indexedRules.get(indexingKey))
.flatMap(Set::stream)
.collect(Collectors.toSet());
}
Final Remarks
The implementation of this indexing mechanism marked a significant breakthrough in our content filtering system. It enabled us to dramatically reduce the time required to filter the entire sports betting catalog, decreasing it from several minutes to mere seconds. This, in turn, empowered us to respond swiftly to any necessary legal adjustments, all the while trimming down the operational costs of maintaining the system.